


A Relaxed Dive into the Architecture of Druid

Hey ByteBeaters! Ready to chill and chat about some seriously cool tech? Today, we're going to take a relaxed yet informative dive into the world of Apache Druid. Whether you're just starting out in data or you’ve been swimming in it for years, this article will give you a clear and enjoyable understanding of Druid’s architecture. Let’s dive in!
Data is the lifeblood of any organisation; traditionally we used data warehousing and BI tools to get insight, creating reports and dashboards once in a while. But times have changed, many companies like Netflix, Salesforce and so on are doing something way cooler. They are using real-time analytics to get instant on-demand insights.

So what is Apache Druid?
Apache Druid is the star of today’s show. It is an Open source, high-performance analytics database designed to power real-time applications. Druid is designed for fast query performance, even on massive datasets. It can execute complex queries and aggregations in milliseconds, enabling interactive and responsive real-time application. It can ingest and analyse large volumes of streaming data in real-time, allowing applications to process and query data as it arrives. This enables instant insights and decision-making based on the most up-to-date information.
It has a distributed architecture that allows it to scale horizontally by adding more nodes to handle increased data volumes and query loads. This elastic scalability makes it suitable for applications with growing data needs. It is designed to be resilient and maintain high uptime, which is crucial for real-time applications that require constant data access. Apache Druid integrates well with other data processing tools like Apache Kafka and Apache Hadoop, allowing for seamless incorporation into existing data pipelines.
Under the Hood: Druid’s Architecture
Apache Druid’s Architecture is like a well-oiled machine, flexible and scalable. It uses a smart storage compute design where services scale independently. Start small on a single machine or go big with thousands of servers. In Apache Druid, data nodes stores pre-fetched, indexed segments, while the query nodes handles the queries. This setup lets Druid ingest millions of events per second and respond queries in under a second.
Efficiency is Apache Druid’s middle name. It minimises unnecessary work by loading only what’s needed for each query, working directly with encoded data, and avoiding needless data transfers. This streamlined approach means Druid can handle massive workloads with ease.
Druid is built to keep going and going. It’s designed for continuous operation with no planned downtime. Data durability is ensured by storing segments in deep storage (cloud or HDFS), making recovery a breeze even in major failures.
The Nuts and Bolts of Apache Druid
Apache Druid runs in a cluster of servers, each playing a specific role. Here are the main players:
Master Nodes: They manage data availability and ingestion
Query Nodes: They accept queries, execute them across the system and then return the results
Data Nodes: They handle data ingestion and storage
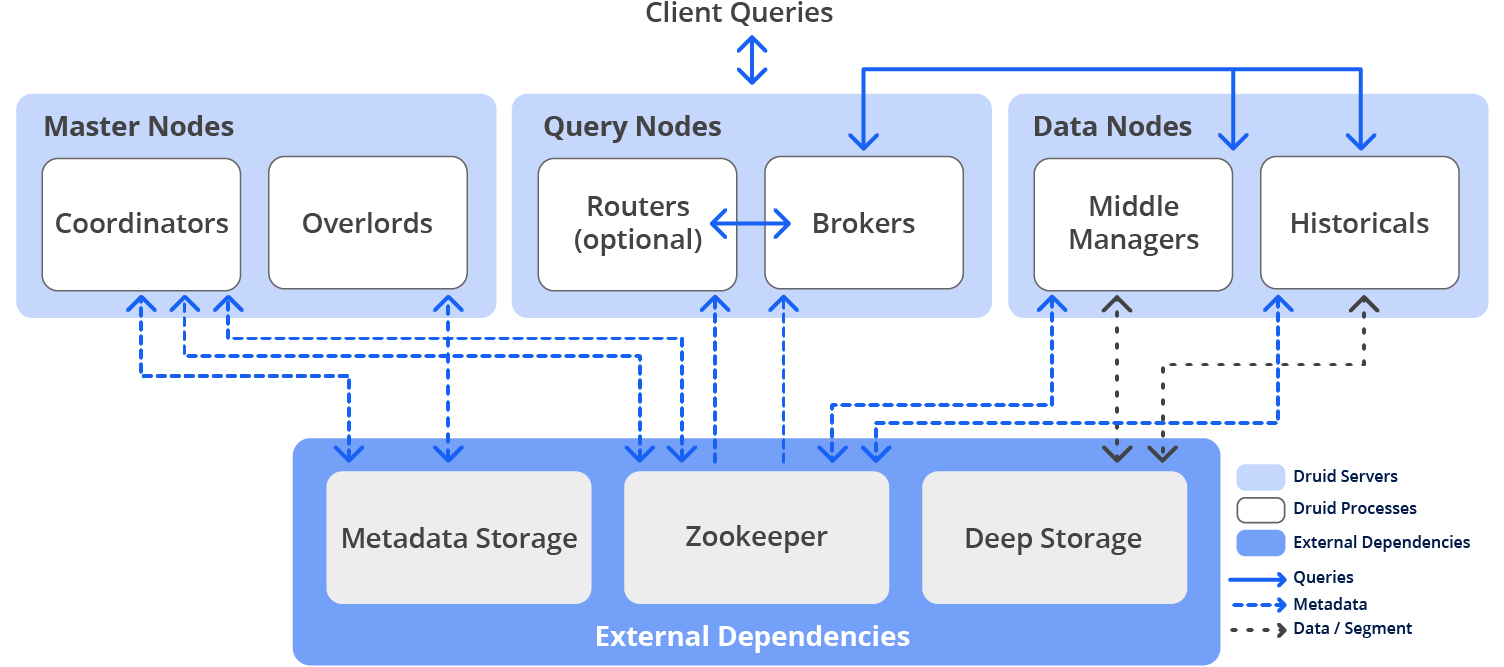
Druid also relies on three external components
Deep Storage: This is where the extra copies of data segments live
Metadata Storage: A relational database keeping tabs on data management
Apache ZooKeeper: It is used for service discovery and leader election
Each node scales independently, allowing Druid to handle varying needs without breaking a sweat.
Druid’s secret sauce is avoiding unnecessary work. It pre-aggregates data, minimises data transfers, and uses long-running processes to keep things snappy. Druid combines the best of both worlds—local and separate storage. Data is preloaded into local caches, ensuring high performance without the high costs usually associated with local storage.

Data is stored in segments, which are single files holding up to a few million rows. This column-oriented storage means Druid only loads the columns needed for each query, making it super efficient.
Druid speeds up searching and filtering by using inverted indexes, specifically compressed bitmaps. Each segment is like a chunk of data that's organised by time. Inside these segment files, data is neatly stored and partitioned, with each column having its own dedicated data structure.

Timestamp and metric columns are compressed using LZ4 to keep things speedy and efficient. Metric columns, typically numeric, are crucial for aggregations and computations. On the other hand, dimension columns play a different role, supporting filter and group-by operations. Each dimension is stored using three distinct data structures to ensure smooth processing.
Check out the three data structures used for the "Name" column in the Dimensions section of the table above:
Dictionary Mapping: This maps each value to an ID for efficient encoding.
Example: { “Simon”: 0, “Andrew”: 1 }
Column Presence List: This list indicates the presence (1) or absence (0) of each value.
Example:
[0, 1, 1, 0]
Bitmaps: These bitmaps show which rows contain each value.
Example for "Simon":
[1, 0, 0, 1]Example for "Andrew":
[0, 1, 1, 0]
These bitmaps act as inverted indexes, speeding up queries and compressing storage.
For filter queries (AND/OR/NOT conditions), these data structures come in handy:
Use the dictionary to find the encoded ID (#1).
Use the bitmaps to fetch rows containing those values (#3).
For group-by with filters:
Use the dictionary for IDs (#1).
Use the bitmaps to get relevant rows (#3).
Group the rows using the column presence list (#2).
These indexes make Druid super-fast for filter and group-by operations, accessing only the necessary rows and columns.

Druid handles both stream and batch ingestion like a pro. Built-in services for Apache Kafka and Amazon Kinesis manage real-time data, while batch ingestion integrates historical data from various sources. This mix makes for a robust, comprehensive analytics setup.
Conclusion
Apache Druid is a marvel of modern tech, designed to meet the demands of real-time analytics. Its scalable, efficient, and resilient architecture makes it a top choice for organisations looking to maximise their data potential. Whether you're dealing with petabytes of data or handling thousands of queries, Druid has got your back.
Stay tuned for more laid-back explorations into the world of data in future ByteBeat editions. Until next time, keep exploring and stay curious!