
Unlocking the Power of Graph Databases and RAG in AI

In the era of advanced artificial intelligence, large language models (LLMs) like ChatGPT have become an integral part of our daily lives. Their ability to fetch and convey information accurately has revolutionised how we interact with technology. However, these models aren't without their challenges, particularly the phenomenon known as "hallucination," where the model generates inaccurate or irrelevant information. To tackle this, one promising approach is Retrieval Augmented Generation (RAG), and its evolution, Graph Retrieval Augmented Generation (GraphRAG).

Understanding RAG and Its Limitations
What is RAG?
RAG combines the best of both retrieval-based and generation-based methods. It interprets user queries, fetches relevant information from a large corpus, and uses this information to generate contextually rich responses. The RAG process typically involves:
Pre-Retrieval: Setting the granularity of data to be searched, ranging from sentence-level to paragraph-level information.
Chunking: Segmenting input data to fit the model's token limits, ensuring efficient information processing.
Retrieval: Searching a database for documents or text segments related to the user’s query.
Post-Retrieval: Integrating the retrieved information into the response generation process.
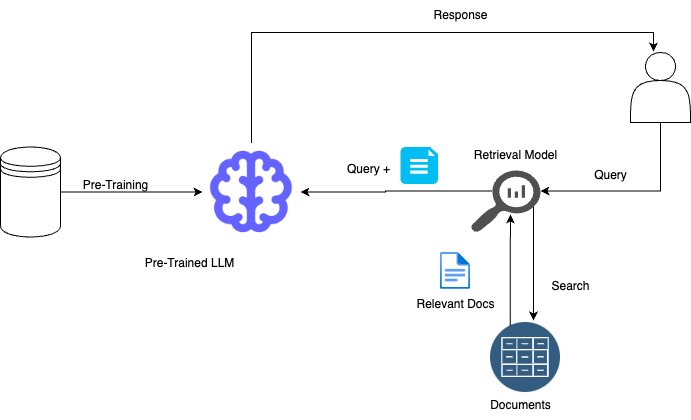
Limitations of RAG
Despite its advantages, RAG has several limitations:
Missing Content: Failing to index relevant documents.
Missed Top-Ranked Documents: Retrieving minimally relevant documents due to subjective retrieval criteria.
Consolidation Strategy Limitations: Ineffective inclusion of crucial documents in the context.
Approximate Values: Tendency to retrieve approximate rather than exact values, leading to inaccuracies.
Incorrect Specificity: Misuse or overuse of user query information.
Incomplete Responses: Generating responses with missing information.
Introducing GraphRAG
What is GraphRAG?
GraphRAG addresses RAG's limitations by integrating graph-based retrieval mechanisms. It reorganises unstructured text into a structured knowledge graph, where nodes represent entities (e.g., people, places, concepts) and edges represent relationships between entities. This structure enables better comprehension and utilisation of the relationships between different pieces of information.
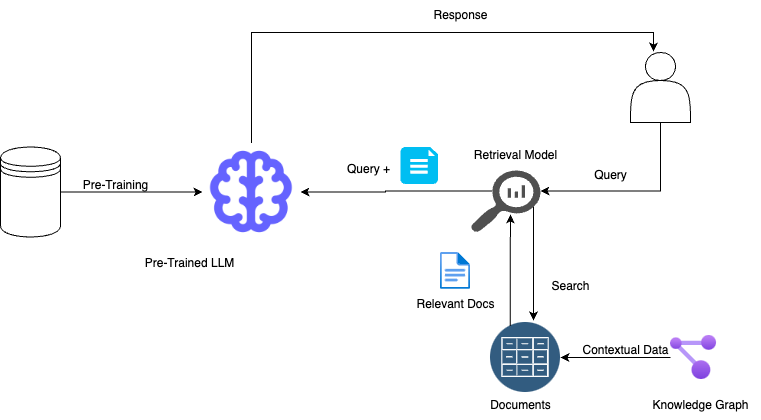
Benefits of GraphRAG
Enhanced Retrieval: GraphRAG leverages knowledge graphs to fetch semantically related documents, improving retrieval accuracy.
Contextual Understanding: Structured knowledge graphs help models understand nuanced relationships, reducing hallucinations.
Better Query Handling: GraphRAG can rewrite user queries to include additional useful context, clarifying user intent.
How GraphRAG Works
GraphRAG operates in four key modules:
Query Rewriting: Adds context to user queries, refining user intent.
Pre-Retrieval & Post-Retrieval: Determines chunking size, indexing methods, and harmonises retrieved data for accurate response generation.
Semantic Search & Similarity Search: Combines semantic search values from knowledge graphs with similarity search values for comprehensive context generation.
Practical Applications and Challenges
Applications
GraphRAG excels in answering complex queries by understanding and leveraging the relationships between entities. For example, it can accurately respond to queries like “How did the scientific contributions of the 17th century influence early 20th-century physics?” by tracing the connections between Newton's laws and Einstein's theories.
Here are some practical examples of where GraphRAG (Graph Retrieval-Augmented Generation) can be effectively utilised:
1. Healthcare and Medical Diagnosis
In healthcare, GraphRAG can be used to provide detailed and accurate medical information by integrating structured medical knowledge bases, such as symptom-disease relationships and treatment guidelines.
Example:
User Query: "What are the potential treatments for a patient with diabetes and hypertension?"
GraphRAG Response: By leveraging a knowledge graph that connects symptoms, diseases, and treatments, GraphRAG can provide a comprehensive answer detailing treatment options that consider the interplay between diabetes and hypertension, referencing up-to-date medical guidelines and research.
2. Financial Services and Risk Assessment
GraphRAG can assist in financial services by analysing complex relationships between financial entities, transactions, and market trends, providing in-depth risk assessments and investment advice.
Example:
User Query: "How did the 2008 financial crisis affect the banking sector globally?"
GraphRAG Response: Using a knowledge graph that maps out historical financial data, market reactions, and interbank relationships, GraphRAG can deliver a detailed analysis of the impact on various banks and the global economy, highlighting key events and their interconnected effects.
3. Legal Research and Compliance
In legal fields, GraphRAG can navigate complex legal documents, case laws, and regulations, offering precise legal research and compliance checks.
Example:
User Query: "What are the legal implications of GDPR on international data transfers?"
GraphRAG Response: By accessing a knowledge graph that includes GDPR clauses, international laws, and case studies, GraphRAG can provide a thorough explanation of GDPR's impact on data transfers, including relevant legal precedents and compliance requirements.
Challenges
Graph RAG faces several significant limitations that impact its efficiency and effectiveness. One major challenge is graph construction. Transforming unstructured text into structured graphs is computationally expensive, requiring significant resources. This process is not only time-consuming but also demands high computational power, making it a critical hurdle in the implementation of Graph RAG.
Another significant challenge is query generation. Large knowledge graphs can become complex and difficult to traverse, complicating the process of generating effective queries. This complexity often leads to inefficient information retrieval, which can severely affect the performance of Graph RAG. Additionally, the reasoning boundary presents a considerable limitation. Optimising the amount of related information included in responses is crucial. However, including too much information can lead to information overload during retrieval, negatively impacting the core function of Graph RAG which is answer generation.
Maintenance of the knowledge graph also poses a significant challenge. Constantly updating the graph to reflect new information is resource-intensive, requiring continuous effort to ensure accuracy and relevance. This ongoing need for updates makes maintenance a persistent issue, demanding substantial resources and effort.
Overall, the challenges in graph construction, query generation, reasoning boundaries, and maintenance highlight the areas where Graph RAG must improve to enhance its overall performance and effectiveness.
Conclusion
GraphRAG represents a significant advancement in AI, offering a robust solution to the limitations of traditional RAG by leveraging the power of knowledge graphs. As research and development continue, GraphRAG has the potential to create more reliable, contextually aware conversational AI systems, paving the way for smarter and more accurate chatbot interactions.
In this rapidly evolving field, staying informed about these technologies and their applications is crucial. By understanding and utilising tools like GraphRAG and Neo4j, we can harness the full potential of AI to deliver precise and context-rich responses, transforming how we interact with machines.