


In the fast evolving field of artificial intelligence, Large Language Models (LLMs) have emerged as powerful tools capable of generating human-like text, answering questions, and assisting with various tasks. However, these models come with a fascinating quirk: they sometimes produce information that is entirely fabricated or inconsistent with known facts. This phenomenon, known as "hallucination," has become a hot topic in AI research and development. But is it a bug that needs fixing, or an inherent feature of how these models work? Let's dive deep into the world of LLM hallucinations.
Understanding Language Models: The Basics
At their core, LLMs are complex statistical models trained on vast amounts of text data. They learn patterns and relationships between words and phrases, allowing them to predict the most likely next word in a sequence. The fundamental operation of an LLM can be distilled to a single, powerful question:
Given a sequence of words, what word is likely to come next?
This probabilistic nature is key to understanding both the power and limitations of LLMs. The probability of generating a sequence of tokens can be expressed mathematically as:
P(x) = P(x₁, x₂, ..., xₙ) = ∏ᵢ₌₁ⁿ P(xᵢ|x₁, ..., xᵢ₋₁)Where x represents a sequence of tokens, and P(xᵢ|x₁, ..., xᵢ₋₁) is the conditional probability of the next token given the previous tokens [1].

The Probabilistic Nature of LLMs
To truly grasp why hallucinations occur, we need to go deeper into the probabilistic foundations of LLMs:
Token Prediction: At each step, the model generates a probability distribution over its entire vocabulary. This distribution represents the model's "belief" about which word should come next. Example: Given the prompt "The cat sat on the...", the model might assign probabilities:
"mat" (30%)
"chair" (25%)
"window" (20%)
"roof" (15%)
Other words (10% combined)
Softmax Output: The final layer of an LLM typically uses a softmax function to convert its internal calculations into this probability distribution. This ensures that all probabilities sum to 1 and allows for the selection of the next token.
Temperature and Sampling: During text generation, LLMs use various sampling techniques to select the next token. A key parameter in this process is "temperature," which controls the randomness of the selection. Lower temperatures make the model more likely to choose high-probability tokens, resulting in more predictable (but potentially repetitive) text. Higher temperatures increase randomness, leading to more diverse (but potentially less coherent) outputs. Example: With a low temperature, the model might consistently complete the sentence as "The cat sat on the mat." With a high temperature, it might occasionally produce more unusual completions like "The cat sat on the chandelier."
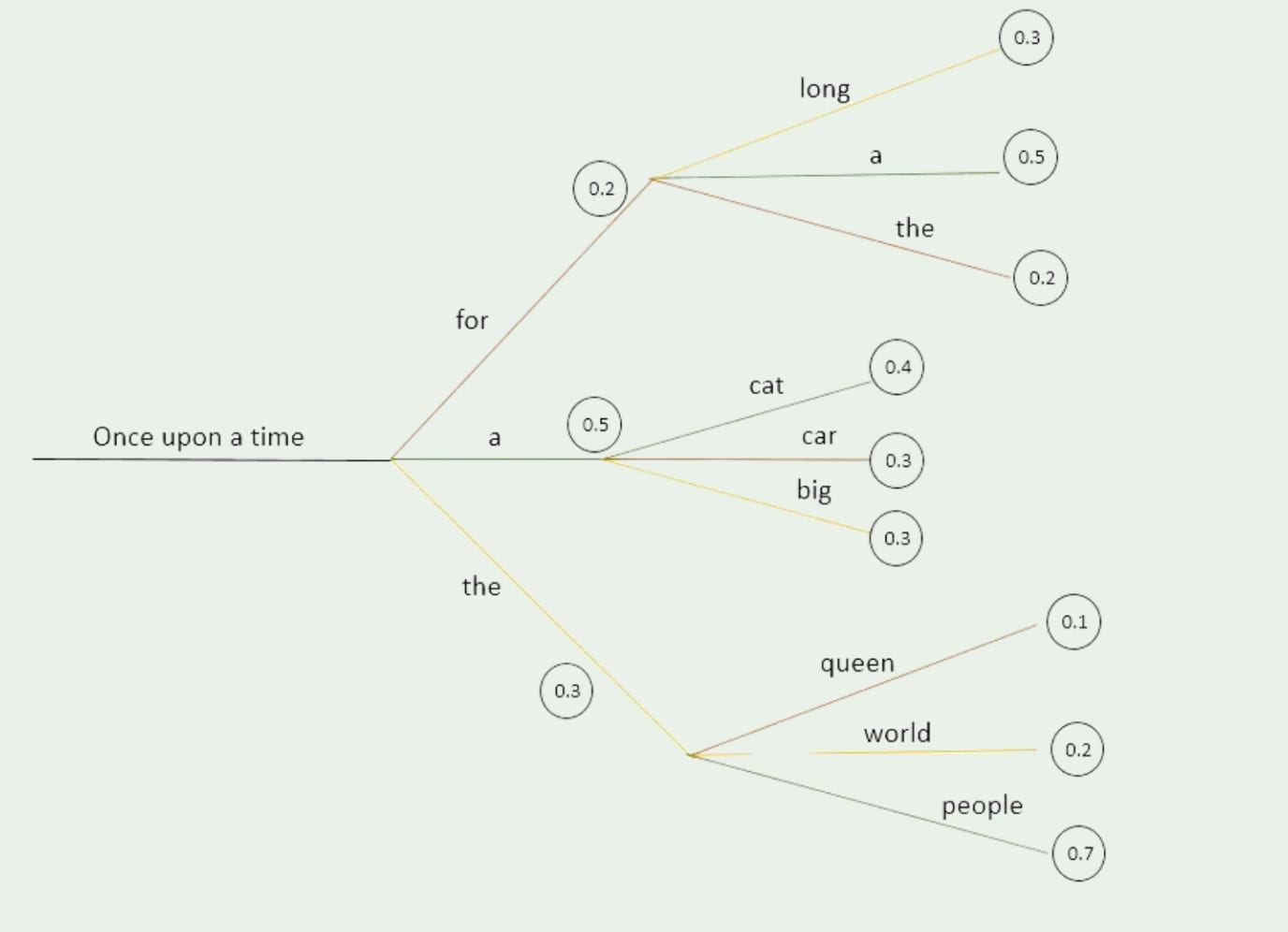
Beam Search: For tasks requiring more coherent outputs, LLMs often employ beam search. This technique explores multiple possible token sequences in parallel, ultimately selecting the most probable overall sequence. In the example “Once upon a time”, the model might consider multiple paths:
"a" (most probable)
"for"
"the"
This probabilistic approach is what allows LLMs to be so flexible and creative. However, it's also the root cause of hallucinations. The model is always making its best guess based on patterns in its training data, but it doesn't have a true understanding of the world or the ability to verify its outputs against external reality.
Real-life example of hallucination: When asked about the capital of France, an LLM might generate:
"Paris" (95% probability)
"Lyon" (2% probability)
"France" (1% probability)
Other cities (2% combined)
While it's highly likely to produce the correct answer (Paris), there's a small but non-zero chance it might confidently state an incorrect answer, like "The capital of France is Lyon."
What Are Hallucinations?
LLM hallucinations occur when these models generate content that is false, fabricated, or inconsistent with their training data. These can range from subtle inaccuracies to completely fictional assertions, often presented with high confidence.
Recent research has identified four main types of hallucinations:
Factual Incorrectness: Providing incorrect information based on existing data.
Misinterpretation: Failing to correctly understand input or context.
Needle in a Haystack: Struggling to retrieve specific, correct information from a vast corpus.
Fabrications: Creating entirely false statements with no basis in the training data [1].
The Underlying Causes of Hallucinations
Compelling evidence suggests that hallucinations are not just occasional errors but an inevitable feature of LLMs. This is due to several fundamental limitations:
Incomplete Training Data: No training dataset can ever be 100% complete or up-to-date. This incompleteness in the training data leads to gaps in the model's knowledge, which it may attempt to fill with plausible-sounding but incorrect information. Example: An LLM trained on data up to 2022 might confidently discuss events from 2023, inventing plausible but entirely fictional details.
Information Retrieval Challenges: Even with complete data, LLMs struggle to retrieve information with perfect accuracy. This is related to the "Needle in a Haystack" problem, which has been proven to be computationally undecidable [1]. Example: When asked about a specific detail from a long text, the model might blend information from multiple similar contexts, creating a coherent but inaccurate response.
Intent Classification Issues: LLMs can misinterpret the context or intent of a query. The probabilistic nature of token prediction means there's always a chance of selecting a token that leads the model down an incorrect path of interpretation. Example: The query "What's the best way to break the ice?" might be interpreted literally about ice-breaking techniques rather than as a question about social interactions.
Undecidability of LLM Halting: The model cannot predict when it will stop generating text, leading to potential inconsistencies. This is analogous to the famous Halting Problem in computer science, which states that no algorithm can determine whether any given program will finish running or continue indefinitely [1]. Example: An LLM might start generating a coherent paragraph but then continue indefinitely, gradually drifting into nonsensical or contradictory statements.
Limitations of Fact-Checking: Even post-generation fact-checking cannot eliminate all hallucinations [1]. The sheer complexity of language and the vast space of possible outputs make perfect fact-checking computationally infeasible. Example: An LLM might generate a detailed, plausible-sounding biography of a fictional person, which would be extremely challenging for an automated system to fact-check comprehensively.
These limitations stem from fundamental mathematical and logical constraints, including the undecidability of certain computational problems like the Halting Problem. The probabilistic nature of LLMs means that even with the best training and safeguards, there will always be a non-zero chance of generating hallucinated content.
The Double-Edged Sword
While hallucinations can be problematic in many scenarios, they also contribute to the creative capabilities of LLMs. The same unpredictability that causes factual errors can lead to novel and imaginative outputs in creative writing or brainstorming tasks.
As noted in recent research:
"Hallucinations themselves are double-edged swords - where the unpredictability causes them to deviate from fact, it also lends them wonderful creative capabilities, as any student who's used them for creative writing assignments will tell you." [1]
Implications and Challenges
The existence of hallucinations in LLMs poses several significant challenges:
Misinformation Risks: Hallucinated content can spread false information, potentially undermining public trust in various domains. This is particularly concerning in an era where information spreads rapidly through social media and other digital channels. Example: An LLM-generated news article containing hallucinated quotes or events could be shared widely before being fact-checked, leading to public misconceptions.
Legal and Ethical Concerns: In fields like healthcare or law, hallucinations could lead to serious consequences. The use of LLMs in these sensitive areas requires careful consideration and robust safeguards. Example: An LLM used in a medical context might hallucinate nonexistent drug interactions or treatment protocols, potentially endangering patient safety if not carefully monitored.
Trust Issues: Repeated exposure to AI-generated hallucinations could erode public trust in AI systems as a whole. This could slow the adoption of beneficial AI technologies across various sectors. Example: Users encountering frequent hallucinations in AI-powered virtual assistants might become skeptical of all AI-generated content, including accurate and helpful information.
Bias Amplification: Hallucinations might reflect or amplify existing biases in the training data [1]. This could perpetuate or exacerbate societal biases and stereotypes. Example: An LLM might hallucinate stereotypical characteristics when asked to describe people from certain backgrounds, reinforcing harmful biases.
Educational Challenges: As LLMs become more prevalent in educational settings, hallucinations could pose challenges for students relying on these models for information or assistance. Example: Students using an LLM for research might unknowingly include hallucinated facts in their assignments, complicating the assessment of their actual knowledge and research skills.
Economic Impact: In business contexts, hallucinations could lead to misinformed decision-making, potentially resulting in significant financial losses. Example: An LLM used for market analysis might hallucinate trends or statistics, leading to misguided business strategies if not cross-verified with other sources.
Mitigation Strategies
While hallucinations cannot be entirely eliminated due to the fundamental nature of LLMs, several strategies are being developed to mitigate their impact:
Chain-of-Thought Prompting: This technique encourages LLMs to make their reasoning process explicit [3]. By breaking down complex queries into step-by-step reasoning, it becomes easier to identify logical inconsistencies that might lead to hallucinations. Example: Instead of directly asking "What will be the population of New York in 2030?", the prompt might be structured as:
What is the current population of New York?
What has been the average annual growth rate in recent years?
Assuming this trend continues, calculate the projected population for 2030.Self-Consistency: This approach involves generating multiple reasoning paths and selecting the most consistent one [4]. It leverages the probabilistic nature of LLMs by assuming that correct answers are more likely to be arrived at consistently across multiple generations. Example: The model might be prompted to solve a math problem multiple times, each with a slightly different approach. The most frequently occurring answer is then selected as the final output.
Uncertainty Quantification: Developing techniques to measure and express the model's confidence in its outputs [5]. This can help users identify potential hallucinations by highlighting when the model is less certain about its predictions. Example: Responses might include confidence scores, such as "I'm 95% certain about this fact" or "This information has a low confidence rating of 30%."
Retrieval-Augmented Generation (RAG): This method combines language models with information retrieval systems to ground responses in verified information [1]. By referencing external, factual knowledge bases during generation, RAG can help reduce the likelihood of hallucinations. Example: When asked about historical events, a RAG-enhanced LLM might first retrieve relevant information from a curated database of historical facts before generating its response.
Controlled Generation: Fine-tuning the sampling temperature and using advanced decoding strategies to balance between creativity and factual accuracy. This approach aims to minimize hallucinations while preserving the model's generative capabilities. Example: Using a lower temperature setting for fact-based queries and a higher temperature for creative writing tasks.
Adversarial Training: Exposing LLMs to adversarial examples during training can help them become more robust against generating hallucinations. This involves deliberately presenting the model with tricky or ambiguous inputs to improve its discernment. Example: Training the model with intentionally misleading questions or statements to improve its ability to detect and avoid potential hallucinations.
Human-AI Collaboration: Developing interfaces and workflows that facilitate effective collaboration between humans and AI, leveraging the strengths of both to minimize the impact of hallucinations. Example: A system where an LLM generates initial drafts or ideas, which are then reviewed and refined by human experts before being finalized.
Continuous Learning and Updating: Implementing systems for regularly updating LLMs with new, verified information to reduce hallucinations stemming from outdated knowledge. Example: A news-focused LLM that is updated daily with verified current events to minimize the generation of outdated or incorrect information.
By combining these strategies and continuing to innovate in the field of AI safety and reliability, we can work towards harnessing the power of LLMs while mitigating the risks posed by hallucinations. However, it's crucial to remember that due to the fundamental nature of these models, some level of hallucination will always be possible, necessitating ongoing vigilance and responsible use practices.
Conclusion: A Feature to Be Managed
Recent research makes a compelling case that hallucinations are an inherent feature of LLMs, rooted in their fundamental mathematical and logical structure. Rather than viewing them solely as a bug to be fixed, we should recognize them as an intrinsic characteristic to be understood, managed, and even leveraged in appropriate contexts.
As we continue to integrate LLMs into various applications, it's crucial for both developers and users to be aware of these limitations. By understanding the nature of hallucinations, we can develop better strategies for using LLMs responsibly, leveraging their strengths while mitigating potential risks.
The future of AI lies not in eliminating hallucinations entirely, but in developing more sophisticated ways to detect, contextualize, and manage them. As we navigate this complex landscape, ongoing research and open dialogue will be essential in harnessing the full potential of LLMs while safeguarding against their limitations.
References
[1] Banerjee, S., Agarwal, A., & Singla, S. (2024). LLMs Will Always Hallucinate, and We Need to Live With This. arXiv preprint.
[2] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. arXiv preprint arXiv:1706.03762.
[3] Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., ... & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903.
[4] Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., & Zhou, D. (2022). Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171.
[5] Abdar, M., Pourpanah, F., Hussain, S., Rezazadegan, D., Liu, L., Ghavamzadeh, M., ... & Nahavandi, S. (2021). A review of uncertainty quantification in deep learning: Techniques, applications and challenges. Information Fusion, 76, 243-297.
