


Prompt caching is an innovative technique revolutionising how we interact with Large Language Models (LLMs). By cleverly storing and reusing pre-computed elements, this innovative approach is set to revolutionise how we interact with Large Language Models (LLMs), making AI conversations faster, more efficient, and more accessible than ever before. paving the way for faster, more efficient AI applications.
Understanding Prompt Caching: The Foundational Concept
At its core, prompt caching is an advanced optimisation technique designed to streamline interactions with LLMs. To grasp its significance, consider the traditional process of communicating with AI models like GPT-4 or Claude. Typically, users send a "prompt" – a text input containing instructions, context, or queries. Processing these prompts, particularly those that are lengthy or intricate, demands substantial computational resources and time.
Prompt caching addresses this challenge by intelligently storing and reusing intermediate computations, known as attention states, that the AI model generates when processing prompts. This approach is especially effective because many prompts contain recurring elements or patterns.
Dr. In Gim and colleagues from Yale University elucidate this concept in their research paper: "Many input prompts have overlapping text segments, such as system messages, prompt templates, and documents provided for context. Our key insight is that by precomputing and storing the attention states of these frequently occurring text segments on the inference server, we can efficiently reuse them when these segments appear in user prompts."
How does Prompt Caching work?
To illustrate the functioning of prompt caching, let's draw an analogy with a sophisticated assembly line in a modern factory:
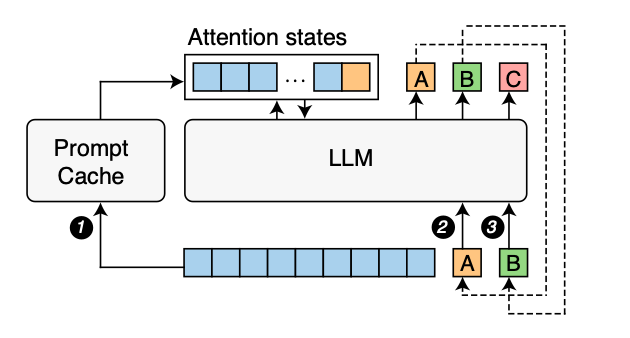
Component Identification: Just as an efficient assembly line identifies common parts used across multiple products, the prompt caching system analyses and breaks down prompts into modular components that are likely to be reused in various requests.
Pre-computation and Storage: Similar to how pre-fabricated components are manufactured and stored for quick assembly, the system calculates and stores the attention states for these reusable prompt components in advance.
Efficient Retrieval: When a new request arrives, the system swiftly retrieves the relevant precomputed states, much like how pre-fabricated parts are quickly pulled from inventory in an assembly line.
Minimal Real-time Processing: Only the unique or new elements of the prompt require processing from scratch, akin to how only custom or specific components need to be manufactured on-demand in a flexible manufacturing system.
This approach significantly reduces the computational overhead for each interaction, leading to faster response times and improved efficiency.
OpenAI's Implementation of Prompt Caching
OpenAI has integrated prompt caching into its GPT-4o, GPT-4o-mini, o1-preview, and o1mini models, with a focus on enhancing performance for extensive prompts. Their implementation includes several key features:
Automatic Activation: The caching mechanism is automatically engaged for prompts exceeding 1024 tokens, eliminating the need for manual activation.
Intelligent Routing: API requests are directed to servers that have recently processed similar prompts, optimising the cache hit probability.
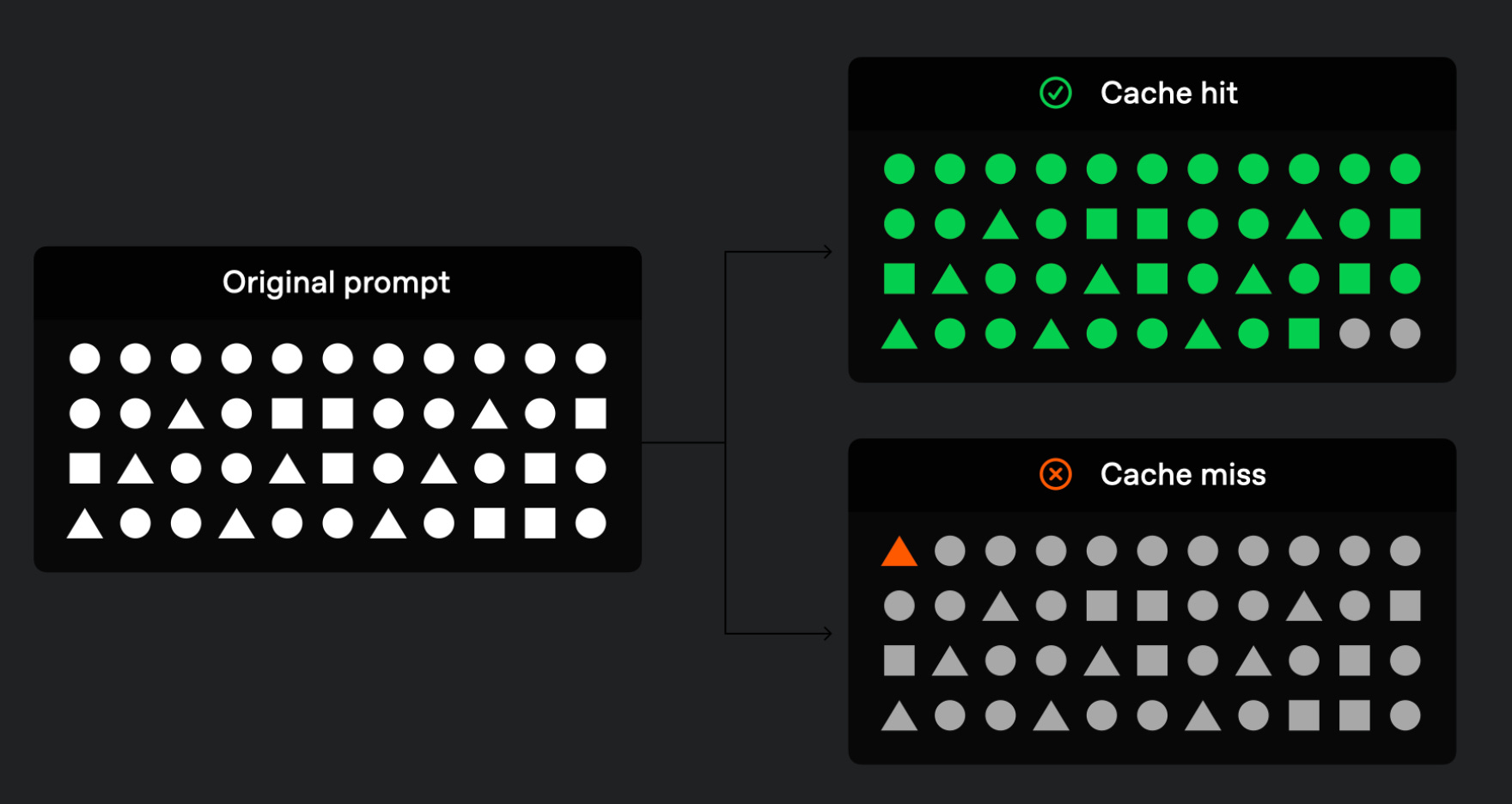
Prefix Matching: The system checks if the initial portion (prefix) of the incoming prompt matches any cached content.
Cache Hit Dynamics:
On a successful match (cache hit), the system utilises the cached result, substantially reducing both latency and operational costs.
In the absence of a match (cache miss), the entire prompt is processed, and its prefix is subsequently cached for future use.
Temporal Cache Management: Cached prefixes remain active for 5-10 minutes during periods of inactivity, extending up to an hour during off-peak times.
Cost Efficiency: Cached input tokens are billed at 50% of the rate for uncached tokens, offering significant cost savings.
Comprehensive Caching Scope: The system can cache various elements, including complete message arrays, images within user messages, tool usage information, and structured output schemas.
Optimisation Guidance: For maximum efficiency, OpenAI recommends structuring prompts with static content at the beginning, followed by dynamic content.
Anthropic's Approach to Prompt Caching
Anthropic, the creator of Claude AI, has developed a distinct methodology for prompt caching:
Customisable Cache Breakpoints: In contrast to OpenAI's automatic approach, Anthropic allows for up to 4 user-defined cache breakpoints, offering greater control over which prompt sections are cached.
Fine-grained Cache Control: Users can manipulate caching behaviour via the cache_control parameter, enabling precise management of the caching process.
Dynamic Cache Lifespan: Anthropic's cache entries have a 5-minute lifespan, which is reset upon each use of the cached content.
Model-specific Implementation: This caching technology is available across Anthropic's Claude model series, including Claude 3.5 Sonnet, Claude 3 Haiku, and Claude 3 Opus.
Extensive Caching Capability: Anthropic's system can cache a wide array of elements, including tool definitions, system messages, user and assistant interactions, images, and tool usage outcomes.
Structured Prompt Design: While Anthropic also recommends placing static content at the prompt's beginning, users must explicitly delineate the end of reusable content using the cache_control parameter.
Model-dependent Caching Thresholds: The minimum cacheable prompt length varies by model:
1024 tokens for Claude 3.5 Sonnet and Claude 3 Opus
2048 tokens for Claude 3 Haiku
CacheGPT: An Alternative Caching Framework
CacheGPT offers a different perspective on caching for LLM applications. While it diverges from the prompt caching method described in the Yale research, it provides valuable caching functionalities for LLM interactions:
Vector-based Similarity Search: CacheGPT transforms user inputs into vector embeddings and conducts a similarity search within the cache storage.
Cache Hit Protocol: Upon finding a match (cache hit), the system utilises the cached response to generate output.
Cache Miss Handling: In the absence of a match, the LLM produces a new response, which is then stored in the cache manager for future reference.
Dynamic Model Selection: CacheGPT can employ an LLM adapter to dynamically select the most suitable model for each request.
Advanced Cache Management: To maintain cache efficiency, CacheGPT implements strategies such as Least Recently Used (LRU) and First-In, First-Out (FIFO).
Comparative Analysis: OpenAI, Anthropic, and CacheGPT
Each approach to prompt caching offers distinct advantages and trade-offs:
Granularity of Caching:
OpenAI and Anthropic focus on prompt-level caching, particularly effective for longer prompts.
CacheGPT operates at a more granular level, potentially caching individual query-response pairs.
User Control and Flexibility:
Anthropic provides the highest degree of user control through cache breakpoints and the cache_control parameter.
OpenAI's approach is more automated, minimising the need for user intervention.
CacheGPT offers programmatic control, allowing developers to fine-tune caching behaviour to their specific needs.
Cross-platform Compatibility:
CacheGPT stands out for its ability to integrate with various LLM providers.
OpenAI and Anthropic's caching mechanisms are tightly integrated with their respective platforms and models.
Implementation Complexity:
OpenAI and Anthropic handle caching primarily on the server-side, simplifying client-side implementation.
CacheGPT requires more extensive setup and management by developers but offers greater customisation potential.
Broader Implications and Future Prospects
The impact of prompt caching extends beyond mere speed enhancements:
Scalability: By reducing the processing load on LLMs, prompt caching enables AI systems to handle a significantly higher volume of requests without a proportional increase in computational resources. This scalability is crucial for applications facing growing user bases or expanding use cases.
User Experience Enhancement: The reduction in response times from seconds to milliseconds transforms the interaction dynamics with AI systems. This responsiveness is key to maintaining user engagement and satisfaction, particularly in applications where real-time interaction is critical.
Energy Efficiency: The reduction in redundant computations translates to lower energy consumption. In an era where the environmental impact of AI is under scrutiny, prompt caching contributes to the development of more sustainable AI solutions.
Democratisation of AI: By lowering the computational requirements and associated costs of running complex AI models, prompt caching makes advanced AI capabilities more accessible to a broader range of organisations and developers. This democratisation could lead to increased innovation and diverse applications of AI across various sectors.
Enhanced Reliability: The reduced processing load and faster response times enabled by prompt caching allow AI systems to handle traffic spikes and high-demand scenarios more gracefully, improving overall system reliability and user trust.
Challenges and Future Research Directions
While prompt caching presents significant advantages, it also introduces new challenges that require ongoing research and development:
Privacy and Security: The storage of cached information raises important questions about data privacy and security. Developing robust encryption methods and secure cache management protocols is crucial to protect sensitive information.
Cache Coherence and Consistency: Ensuring that cached information remains accurate and up-to-date, especially in rapidly changing contexts, is a significant challenge. Advanced cache invalidation and update strategies are needed to maintain data consistency.
Resource Optimisation: Balancing the memory requirements of caching against the computational savings it provides is an ongoing area of research. This includes developing intelligent cache eviction policies and exploring hierarchical caching strategies.
Adaptive Caching Strategies: Future research may focus on developing more sophisticated, context-aware caching mechanisms that can dynamically adjust caching behaviour based on usage patterns, user preferences, and system load.
Cross-Model Compatibility: As the AI landscape continues to evolve, developing caching strategies that can work effectively across different LLM architectures and versions will be crucial for broader adoption and interoperability.
Conclusion
Prompt caching represents a significant leap forward in optimising interactions with Large Language Models. By intelligently managing computational resources and reducing redundant processing, it paves the way for more responsive, efficient, and accessible AI applications. As research in this field progresses, we can anticipate even more sophisticated caching strategies that will further enhance the capabilities and reach of AI technologies.
The advent of prompt caching is not merely a technical optimisation; it's a transformative development that has the potential to reshape how we interact with AI systems across various domains. As this technology matures, it will likely become an integral component of AI infrastructure, enabling more natural, efficient, and powerful AI-driven solutions in fields ranging from healthcare and finance to education and scientific research.
As we continue to push the boundaries of what's possible with AI, techniques like prompt caching will play a pivotal role in making these advanced technologies more accessible, efficient, and impactful in our daily lives and across industries.

Share this post